Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
on Review
Abstract
이미지는 텍스트와 달리 스케일이 다양하고 고해상도를 갖기 때문에 텍스트에 사용되던 Transformer를 비전 분야에 적용하는 것은 어렵다. Swin Transformer는 이런 문제를 해결하기 위해 Shifted Windows를 사용하는 계층적인 Transformer를 제안한다. 어텐션 영역을 겹치지 않는 윈도우로 제한하여 효율성을 높이고, 이미지 크기에 대해 선형적인 계산 복잡성을 제공한다. 또한, 다양한 스케일에 대한 모델링 유연성을 갖고 모든 MLP 아키텍처에 적용가능하다.
1. Introduction
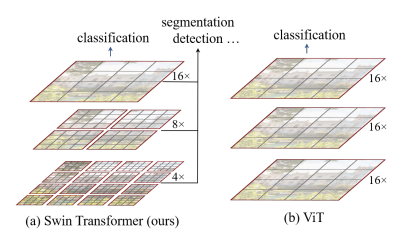
기존 Vision Transformer는 저해상도의 단일 피쳐맵에 대해서 전역적인 어텐션을 수행했다. 반면, Swin은 계층적인 피처맵을 구성하며 각 윈도우 내에서만 어텐션을 수행하므로 이미지 크기에 대해 선형적인 계산 복잡도를 가진다.
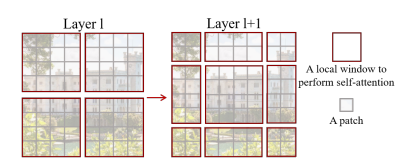
Swin Transformer의 핵심 디자인 중 하나는 Shifted Window이다. 먼저 일반적인 Window Partioning으로 셀프 어텐션을 수행하고 다음 레이어에서 partion을 이동시킨 후 새로운 window기반의 셀프 어텐션을 수행한다. 새로운 window는 이전 레이어의 윈도우간 경계를 포함한다.
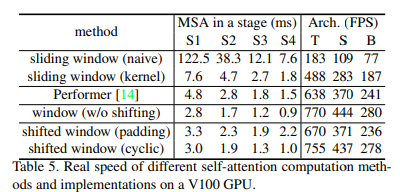
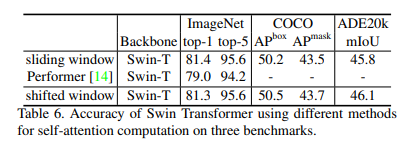
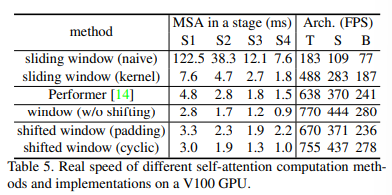
이전의 Sliding Window기반의 어텐션은 쿼리마다 다른 key를 공유하지만 Shifted Window는 동일한 key를 공유하므로 하드웨어에서 메모리 엑세스가 용이하다. 위의 Table5,6에서도 알 수 있듯이 모델링 파워는 비슷하지만 FPS가 훨씬 개선된 것을 확인할 수 있다.
2. Related Work
CNN and variants CNN은 여전히 중요한 비전 네트워크지만 Tranformer같은 구조들이 기본적인 비전 인식 태스크에서 매우 좋은 성능을 달성했고, 이를 통해 비전과 언어를 통합 모델링 할 수 있을 것으로 기대한다.
Self-attention based backbone architectures
과거 논문들에서 특정 영역 내에서만 어텐션을 수행하는 방법을 제안하여 ResNet보다 높은 성능을 달성했다. 그러나 이들은 메모리 엑세스에 비용이 많이 드므로 convolution 네트워크보다 더 큰 지연시간을 발생한다. Swin Transformer는 Shift Windows를 사용하여 하드웨어에서 더 효율적인 구현이 가능하다.Self-attention/Transformers to complement CNNs
CNN에 self-attention layer나 transformer를 추가하는 연구도 있다. Swin은 기본적인 시각적 피처 추출에 transformer를 적용한다.Transformer based vision backbones
우리 연구와 가장 관련 있는 것은 Vision Transformer부분이다. 기존 ViT는 중간 크기 정도의 이미지 패치에 Transformer를 적용한다. 높은 성능에 달성하는 대신 대규모의 훈련 데이터셋(JFT-300M)이 필요하다. DeiT는 ViT가 적은 데이터셋(ImageNet1K)를 사용하여도 효과적인 성능을 내는 방법 몇 가지가 소개 되었지만 ViT는 이미지 해상도가 높은 경우엔 적합하지 않다. 왜냐하면 복잡성이 이미지의 크기에 따라 제곱으로 증가하기 때문이다. ViT를 개선한 다른 연구들도 여전히 이미지 크기에 따라 제곱적으로 복잡성이 증가한다. 반면, swin은 선형적인 증가를 제안한다.
3. Method
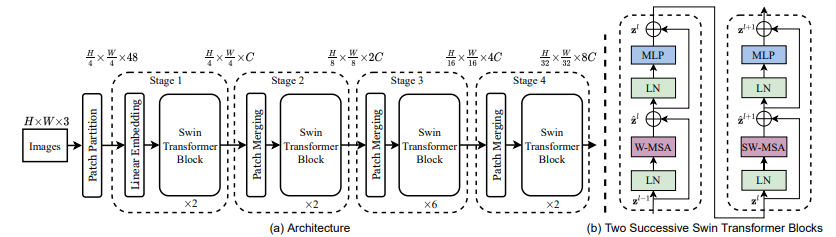
Overall Architecture
총 4개의 단계로 구성되어 있다. 각 Stage는 PatchMerging하여 해상도 조정하는 부분과 SwinBlock으로 구성되어 있다. 각 단계별 SwinBlock의 갯수는 [2,2,6,2]개이다.
먼저 input이미지를 4x4크기의 패치로 나눈다. 4x4크기로 나눈 후에 하나의 패치 뒤로 나머지 세 개를 임베딩 시킨다고 생각하면 돼서 이미지의 크기는 1/4로 줄고, 3채널 이미지 이므로 4x4x3 = 48차원이 된다. 이게 stage1의 input이 된다. stage1의 결과를 stage2로 넣고 그 결과를 또 stage3에 넣는 방식이다. 각 stage에서는 해상도를 조절하기 위한 PatchMerging이 수행되는데, 주변의 Patch들을 하나로 합치므로 이미지의 크기는 1/2씩 줄어든다. 임베딩 차원은 stage별로 각각 [96,192,384,768]이다.
Swin Transformer Block은 두 개가 연속으로 붙어있는 것이 기본 구조이다. 일반적인 Window Attention을 진행하고 다음 블럭에서 Shifted Window Attnetion을 진행한다.
블럭은 두 개 층의 MLP가 GELU함수와 함께 사용되고 각 MSA모듈과 MLP이전에는 LayerNorm레이어가 있으며, 각 모듈 이후에는 Residual Connection이 적용된다.
Shifted Window based Self-Attention
이미지 전역에 대해 어텐션하는 것은 이미지 크기에 대해 계산량이 제곱으로 증가하므로 적절하지 않다. 따라서, 효율적인 모델링을 위해 로컬 윈도우 내에서만 어텐션을 계산한다. 윈도우는 이미지를 겹치지 않게 분할하고 각 윈도우가 M x M개의 패치를 포함한다고 할 떄, 계산복잡도는 다음과 같다.
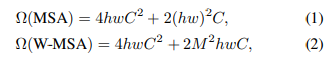
- h : 이미지의 height
- w : 이미지의 width
- C : 이미지의 채널
(1) 전역 어텐션은 이미지 크기에 따라 계산량이 제곱으로 증가한다
(2) 로컬 어텐션은 각 윈도우의 크기가 일정하므로 이미지 크기와 관련없이 선형의 복잡도를 갖는다.
그러나, 윈도우 기반의 self attention은 윈도우 간의 연결이 부족하다. 따라서, shifted window partitioning을 도입하여 윈도우 간의 연결성을 보완한다. 첫 번째는 일반적인 윈도우 분할을 하고 두 번째는 (윈도우크기/2,윈도우크기/2)만큼 이동한다. 식으로 나타내면 다음과 같다.

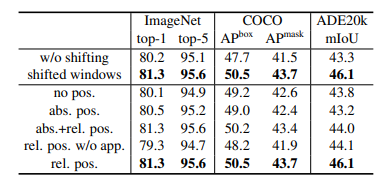
shifted window의 성능은 분류,인식,분할 모든 태스크에 대해 효과적이다.
Shifted window의 문제 중 하나는 shift하다보면 윈도우가 M x M보다 작은 경우가 생기는 것이다. 이때 비어 있는 부분을 패딩해서 M x M 으로 만든 후 패딩된 부분은 마스킹하면 되지만 이는 많은 계산량이 요구된다. 따라서, Cyclic shift를 사용하여 효율적인 계산을 제안한다. 단, cyclic shift한 부분은 피처맵 상에서 인접하지 않으므로 계산시 그냥 마스킹해버린다. Cyclic shift는 배치 윈도우의 수가 일반적인 윈도우 분할의 경우와 동일하게 유지되므로 효율적이다. attention 끝나면 다시 원래대로 돌리는 Reverse cyclic shift를 진행한다.
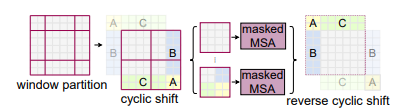
padding과 cyclic shift의 결과를 아래 표에서 비교해보면 stage별 소요시간이 감소하고 FPS가 증가함을 알 수있다.
Relative position bias
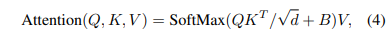
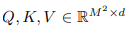
Architecture Variants
T,S,B,L 버전의 Swin Transformer가 있음

FLOPs 비교해보면 큰 모델일수록 FLOPs가 큼
4. Experiments & results
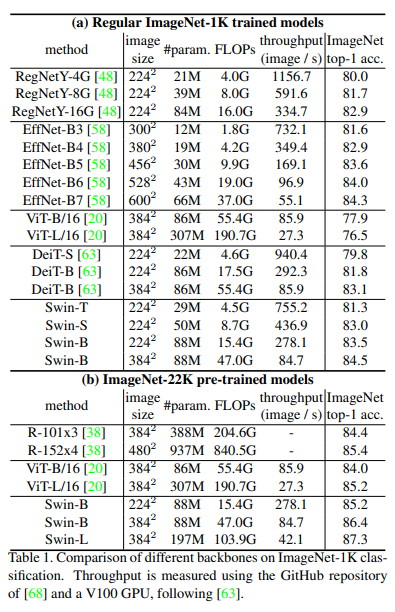
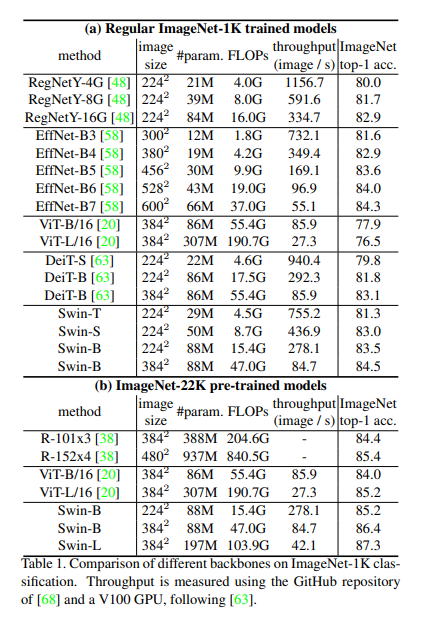
4.1. Image Classification on ImageNet-1K
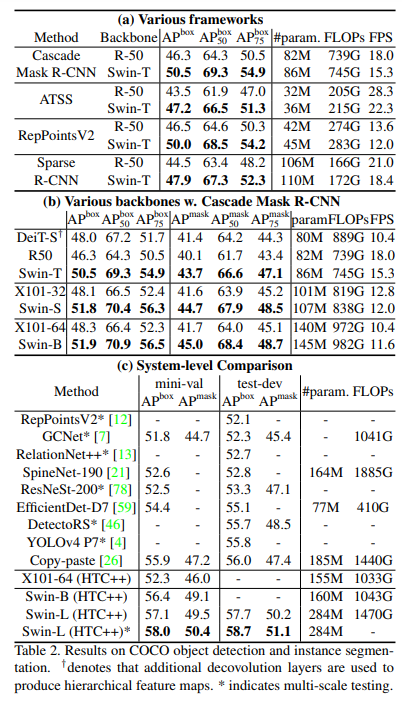
4.2. Object Detection on COCO
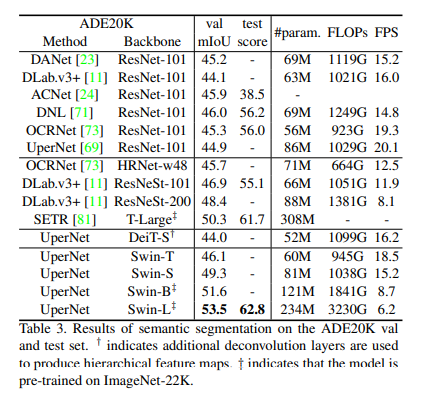
4.3. Semantic Segmentation on ADE20K